|
一、项目背景:为什么需要用机器学习预测市场? 股市波动受政策、资金、情绪等多重因素影响,传统技术分析依赖人工解读 K 线、均线等指标,不仅耗时,还容易受主观判断干扰。随着机器学习技术的发展,通过算法挖掘历史数据中的隐藏规律,成为辅助分析的新工具。 本项目(AI stock Predictor)正是基于这一思路,整合了线性回归、支持向量回归(SVR)、神经网络(NN)和长短期记忆网络(LSTM)四种算法,通过历史股价数据训练模型,实现对未来价格的预测。需要特别说明的是,项目明确标注 “预测结果不精准,不可用于实际投资决策”,其核心价值在于为新手提供 “算法实战练习场”,理解机器学习在时间序列预测中的应用逻辑。
二、项目优势:4 大核心特点让新手快速上手多算法对比,直观理解差异项目没有局限于单一模型,而是同时实现了线性回归(传统统计方法)、SVR(核函数思想)、神经网络(浅层非线性拟合)和 LSTM(处理时序依赖的深度学习模型)。通过对比四种模型的预测误差(如 R² 分数、百分比差异),能直观看到不同算法在时序数据上的表现差异 —— 例如 LSTM 通常在长序列依赖问题上更优,而线性回归解释性更强。 完整的数据链路,从获取到预处理 项目从雅虎财经(Yahoo! Finance)API 获取历史数据(包含开盘价、收盘价、成交量等),并内置了完整的预处理流程:
缺失值处理:通过前向填充(ffill)和后向填充(bfill)处理交易日空缺; 特征工程:构建滞后特征(如前 5 天的价格),将时序数据转化为模型可接受的输入格式;数据归一化:使用 StandardScaler 消除量纲影响,提升模型收敛速度。代码模块化,逻辑清晰易读 项目将功能拆分为数据获取(dataRetrieval.py)、模型定义(StockPredictor.py)、主程序(main.py)等模块。例如 AI stock Predictor 类中,每个算法都有独立的 train 和 predict 方法,新手可单独调试某一模型,降低学习门槛。 可视化辅助,结果一目了然通过 matplotlib 实现预测结果与真实数据的对比图、训练过程中的损失曲线(losses.png)等,帮助理解模型拟合效果。例如 plot_results 函数可直观展示预测值与真实值的偏差,让 “模型是否有效” 有可视化依据。
三、实战指南:从零开始运行项目1. 环境搭建
项目依赖 Python 3.5 及多个库,推荐使用 conda 管理环境。根据 project.yml 文件,执行以下命令创建环境: # 克隆项目到本地git clone https://github.com/Nazanin1369/stockPredictor.gitcd stockPredictor# 创建conda环境conda env create -f project.ymlconda activate naz# 创建conda环境2. 数据准备
项目通过 yahoo_finance 库获取数据,可直接运行 dataRetrieval.py 获取指定股票的历史数据(以亚马逊为例): # 在src/dataRetrieval.py中修改参数并运行retrieveStockData( tickerSymbol='AMZN', # 股票代码 startDate='1997-05-15', # 起始日期 endDate='2016-04-27', # 结束日期 fileName='./data/lstm/AMZN.csv' # 保存路径)
运行后,数据会以 CSV 格式保存,包含调整后收盘价(Adj_Close)等核心指标。 3. 模型训练与预测
以 main.py 为例,可一键运行四种算法的训练和预测流程,核心代码解析如下: # 导入模块import StockPredictor# 配置参数startDate = '2010-01-01'endDate = '2013-08-19'ticker = 'GOOG' # 谷歌股票metric = 'Adj_Close' # 预测目标:调整后收盘价queryDate = '2013-08-20' # 待预测日期# 初始化预测器sp = StockPredictor.StockPredictor()# 加载并预处理数据sp.loadData(ticker, startDate, endDate, reloadData=False)sp.prepareData(queryDate, metric=metric, sequenceLength=5) # 用前5天数据预测# 线性回归预测sp.trainLinearRegression()predicted_lr = sp.predictLinearRegression()print(f"线性回归预测值:{predicted_lr},真实值:{actual}")# LSTM预测(深度学习模型)sp.trainRNN()predicted_rnn = sp.predictRNN()print(f"LSTM预测值:{predicted_rnn},真实值:{actual}")
运行后,控制台会输出四种模型的预测结果、R² 分数(衡量拟合优度,越接近 1 越好)、百分比误差等指标。例如: R2 score for test set (LSTM): 0.7823.实际价格:520.35,LSTM预测值:518.62百分比差异:0.33%
4. 结果解读- 若某模型的 R² 分数接近 1,说明其对历史数据的拟合效果好,但需注意 “过拟合” 风险(训练集分数高,测试集分数低);
- 对比不同模型的百分比差异,可观察哪种算法在该股票数据上表现更稳定;
- 损失曲线(losses.png)展示训练过程中误差的下降趋势,若曲线震荡不收敛,可能需要调整迭代次数(epochs)或批次大小(batch_size)。
四、新手常见问题数据获取失败?
雅虎财经 API 可能存在访问限制,可尝试更换网络环境,或直接下载 CSV 文件放入 data 目录,设置 reloadData=False 避免重复请求。 模型预测误差大?
股市受突发因素影响大,历史数据难以完全预测未来。可尝试调整 sequenceLength(如从 5 改为 10,增加输入序列长度),或增加训练数据的时间跨度。 LSTM 训练慢?
LSTM 作为深度学习模型,计算量较大,可减少 epochs(如从 150 改为 50),或在低配置设备上优先测试线性回归、SVR 等轻量模型。
五、总结
本项目通过 “多算法对比 + 完整流程实现”,为新手提供了理解机器学习预测时序数据的绝佳案例。它不只是一个 “股票预测工具”,更是一个学习数据预处理、模型调优、结果评估的实践平台。需要再次强调:市场波动复杂,任何模型都无法精准预测,本项目的价值在于技术学习,而非投资指导。
看完了么?
动手能力强的可以自己动手部署一个,
但是自己不懂编程,从0基础开始学可能需要半年入门,到真正能够制作出了就......大概率中途放弃
一万年太久,只争朝夕
全球从硅谷、微软、英特尔等裁员下来的几十万一流工程师怎么不用? 目前他们处于空窗期,论坛与这些人在线协作部署好了一键启动版本,推广期仅需手工费500元,或者1000积分兑换。
| 
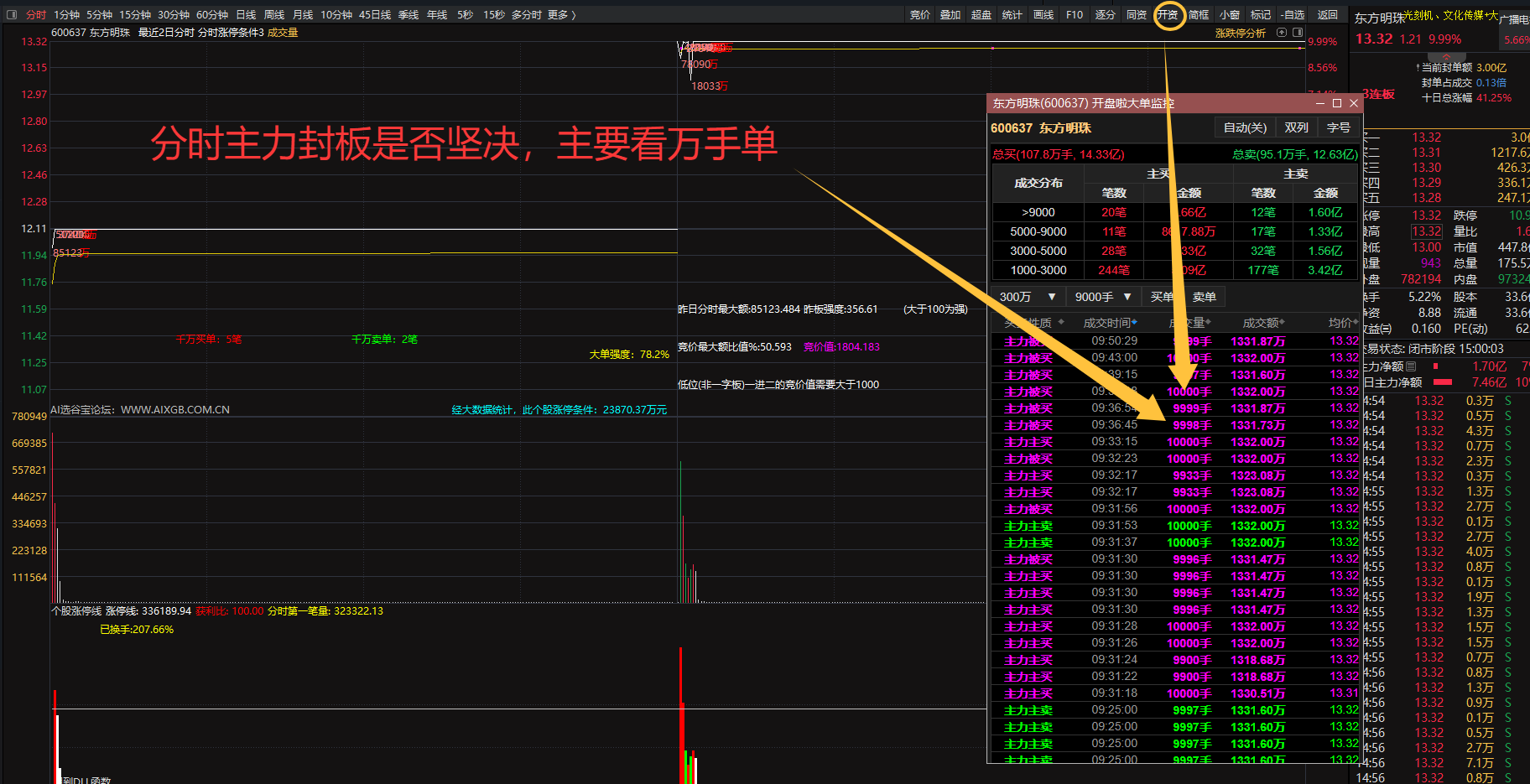
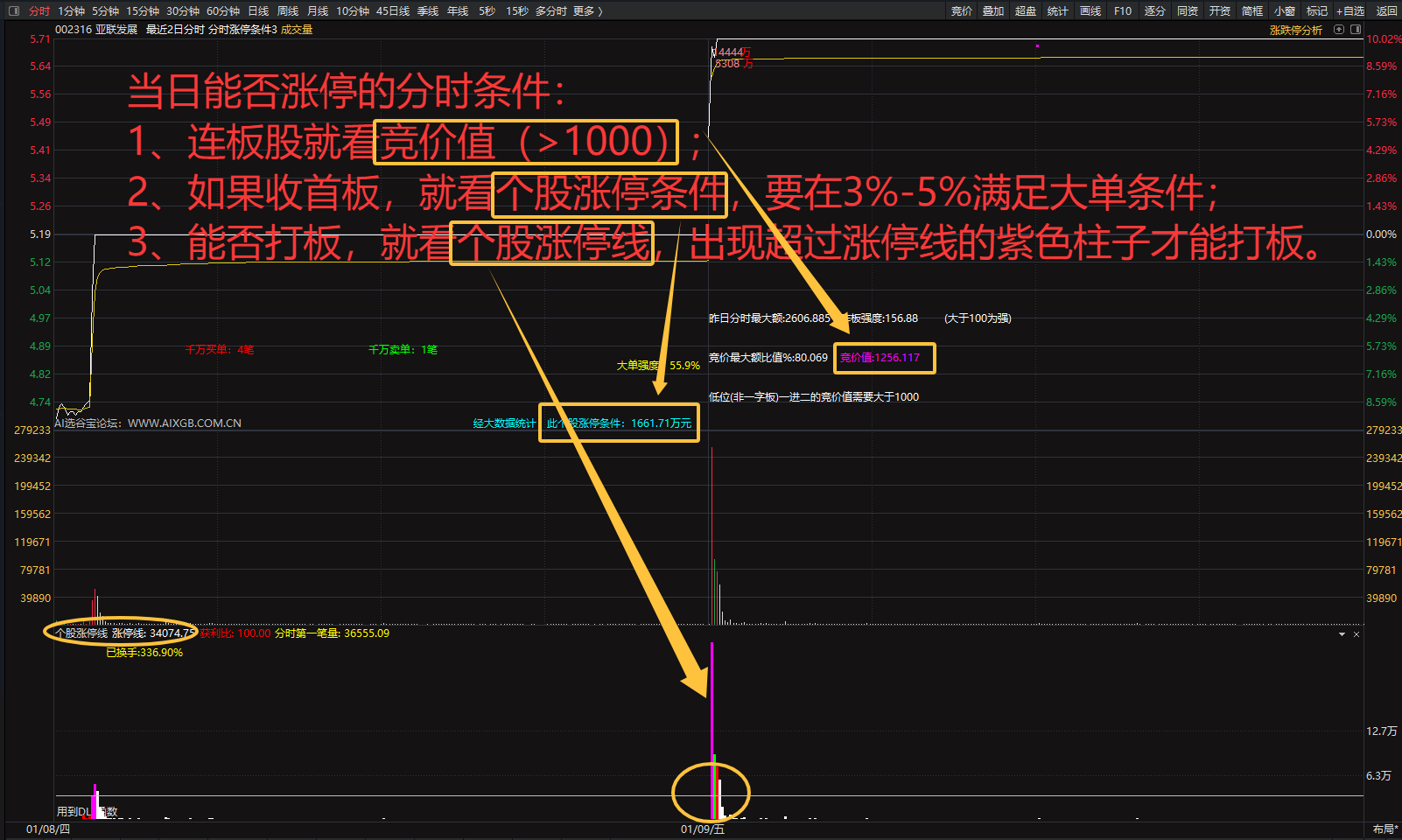
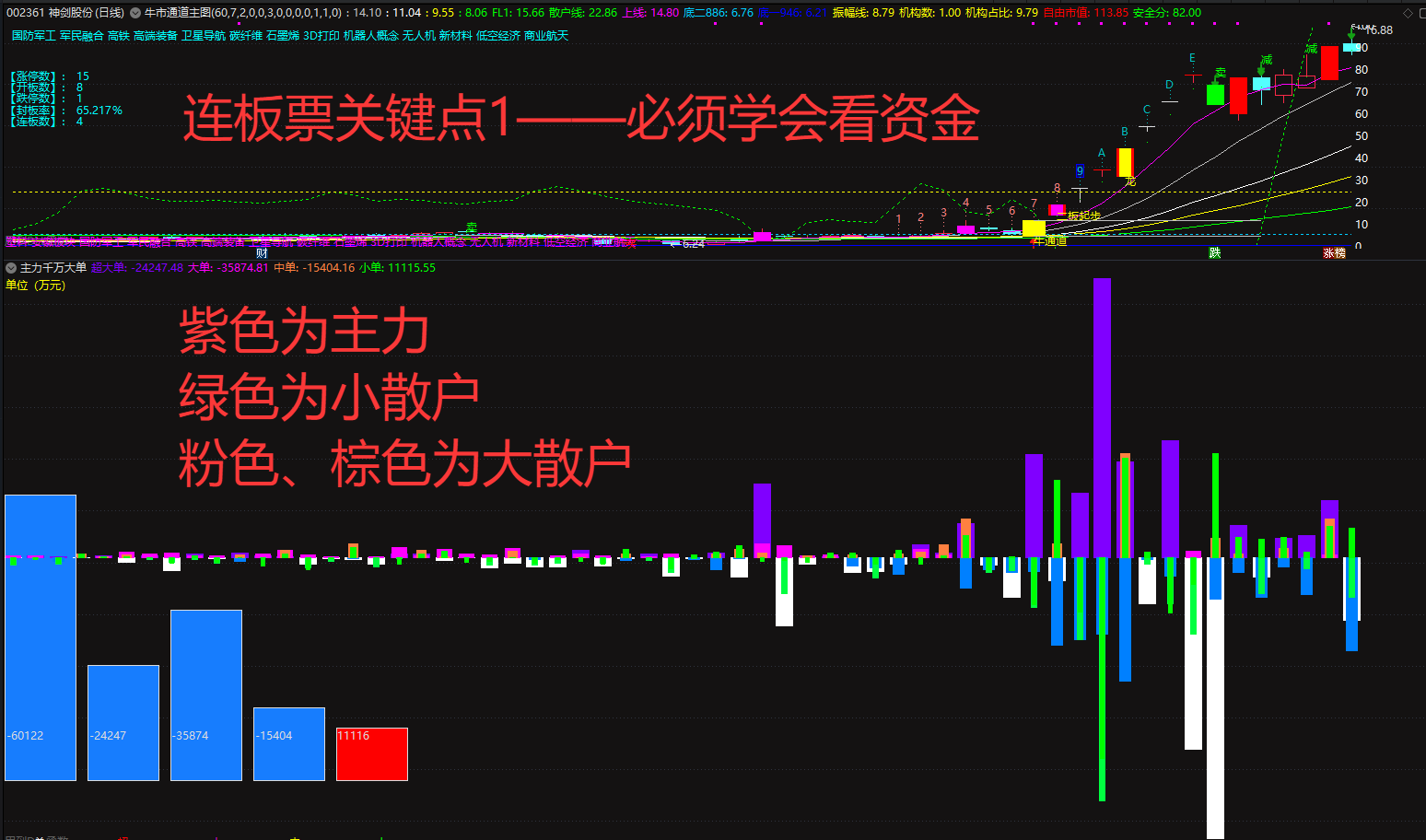
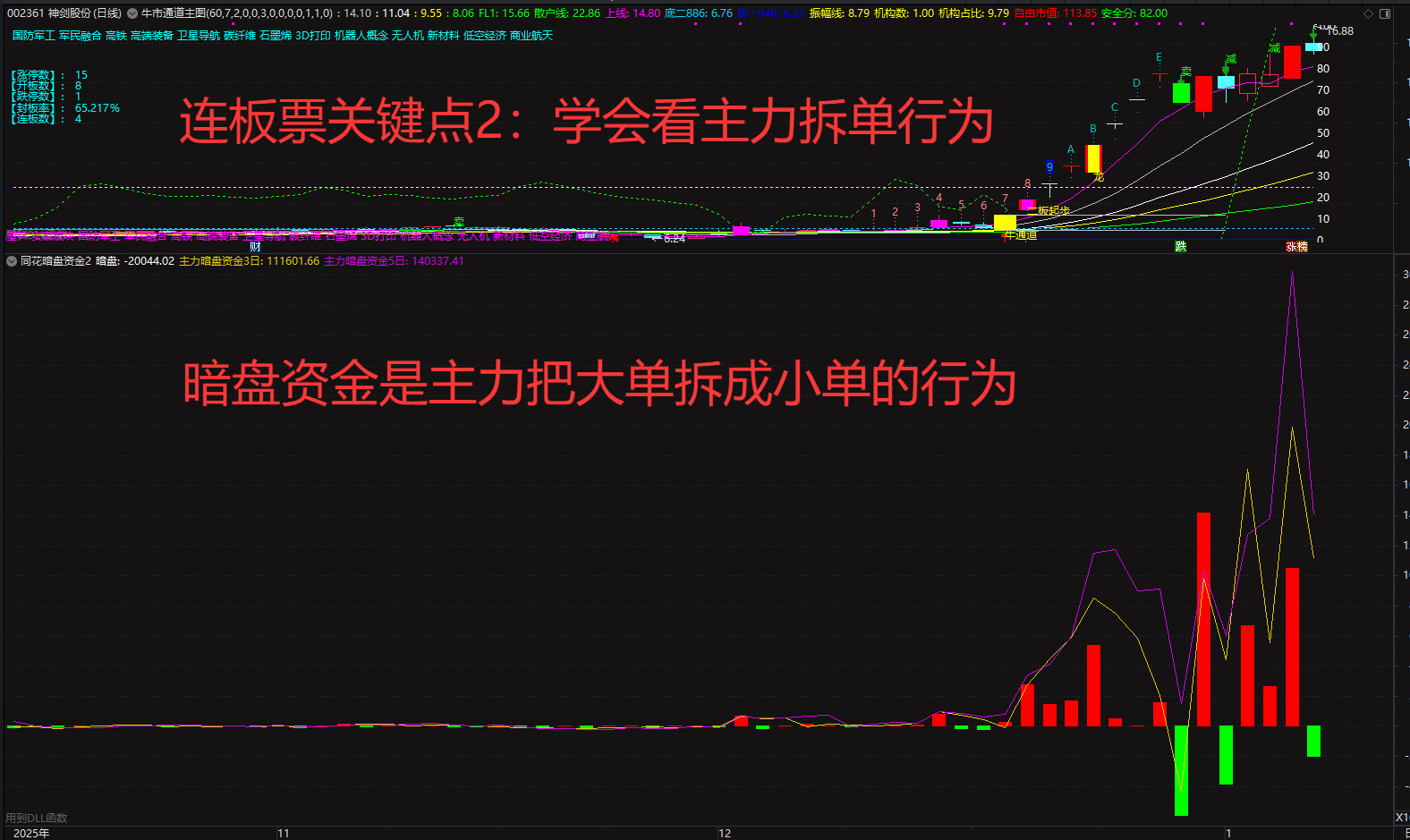

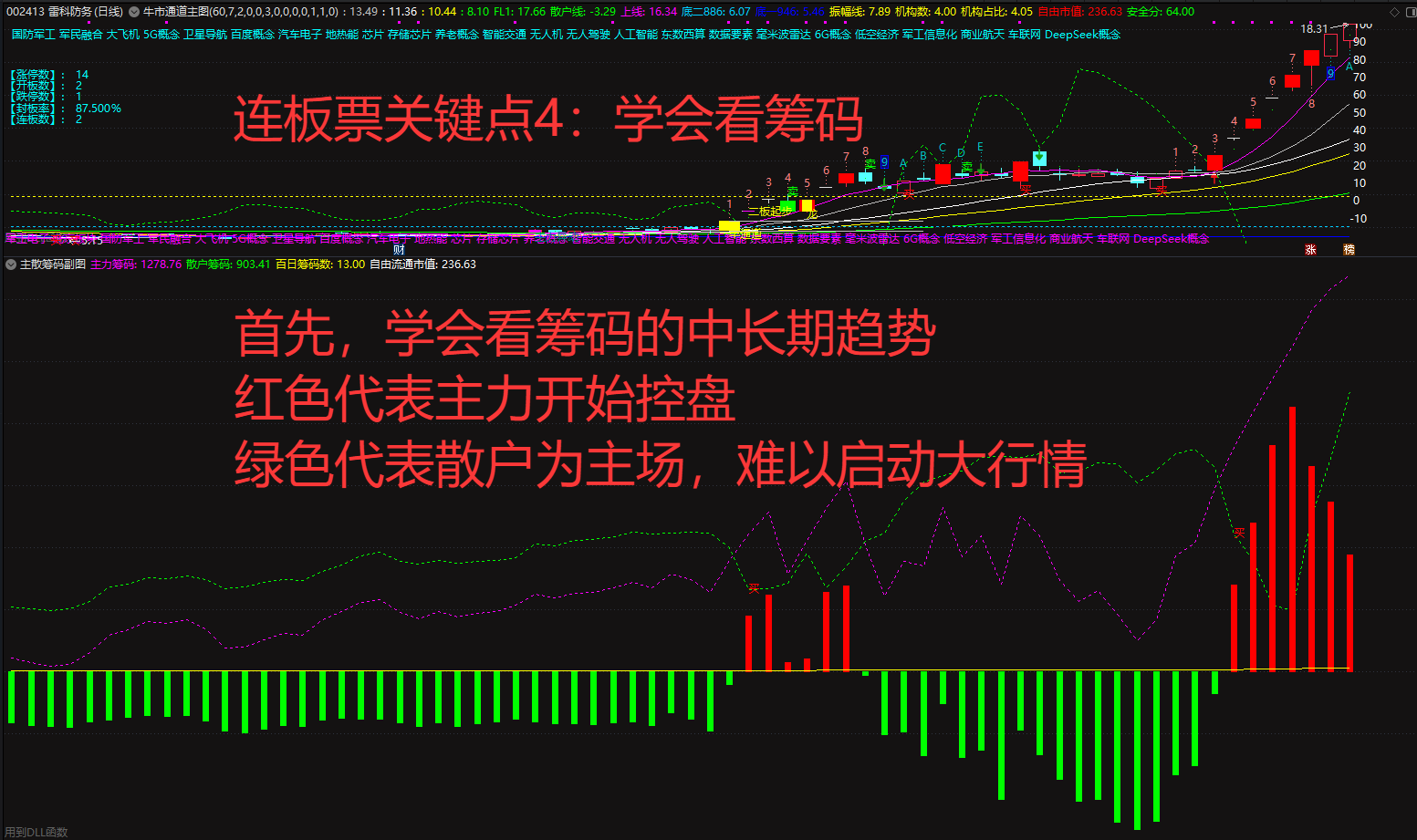
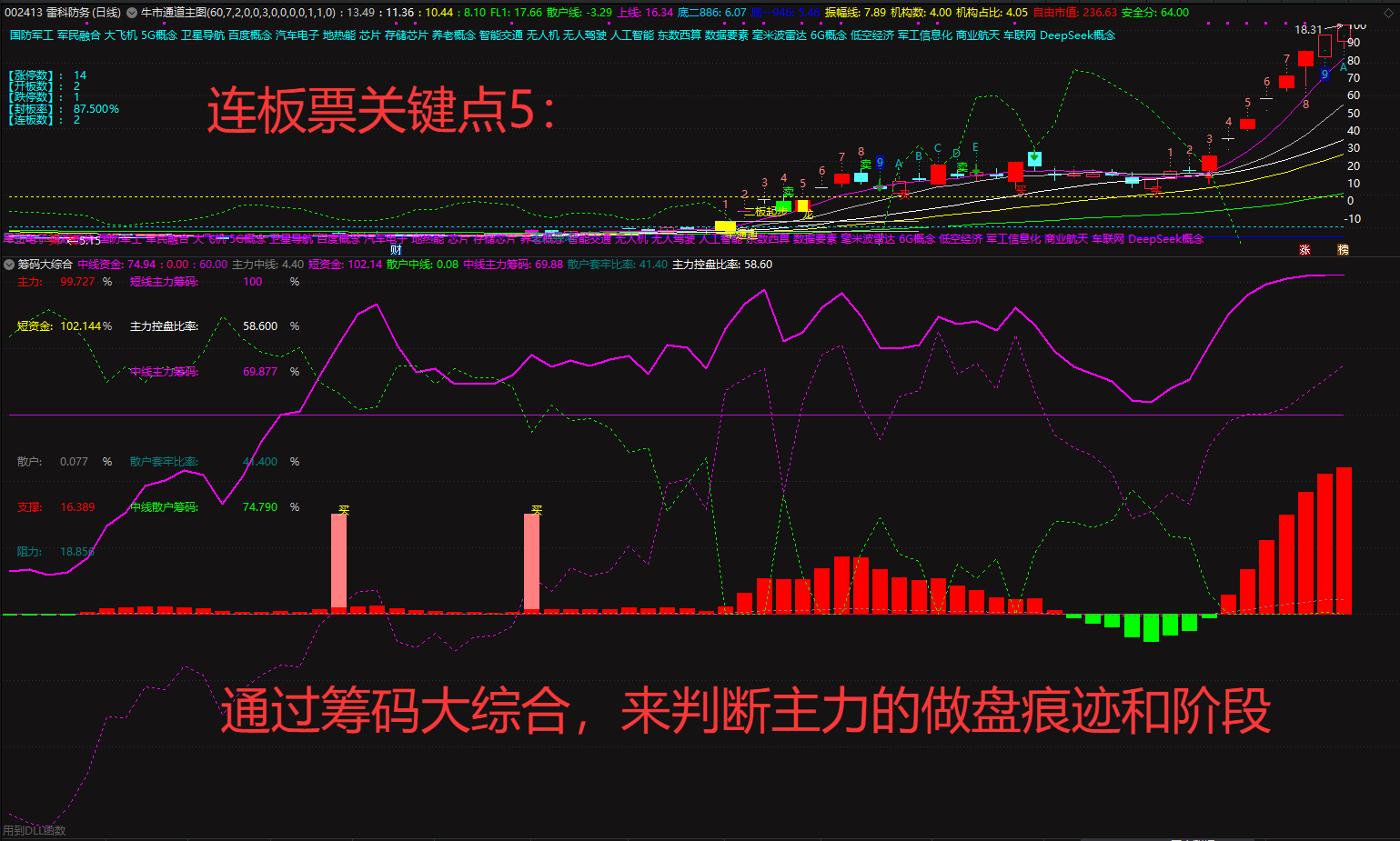
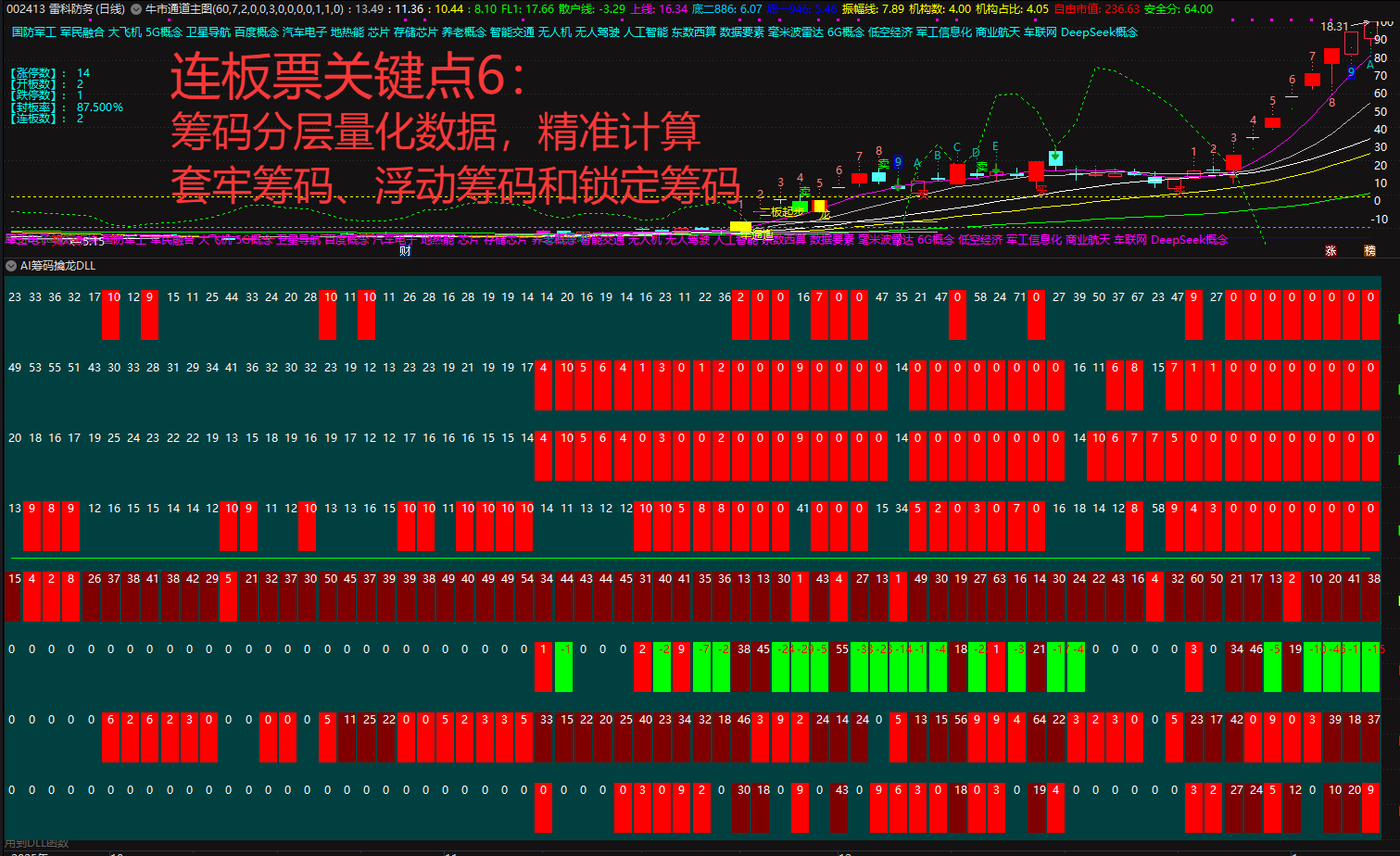


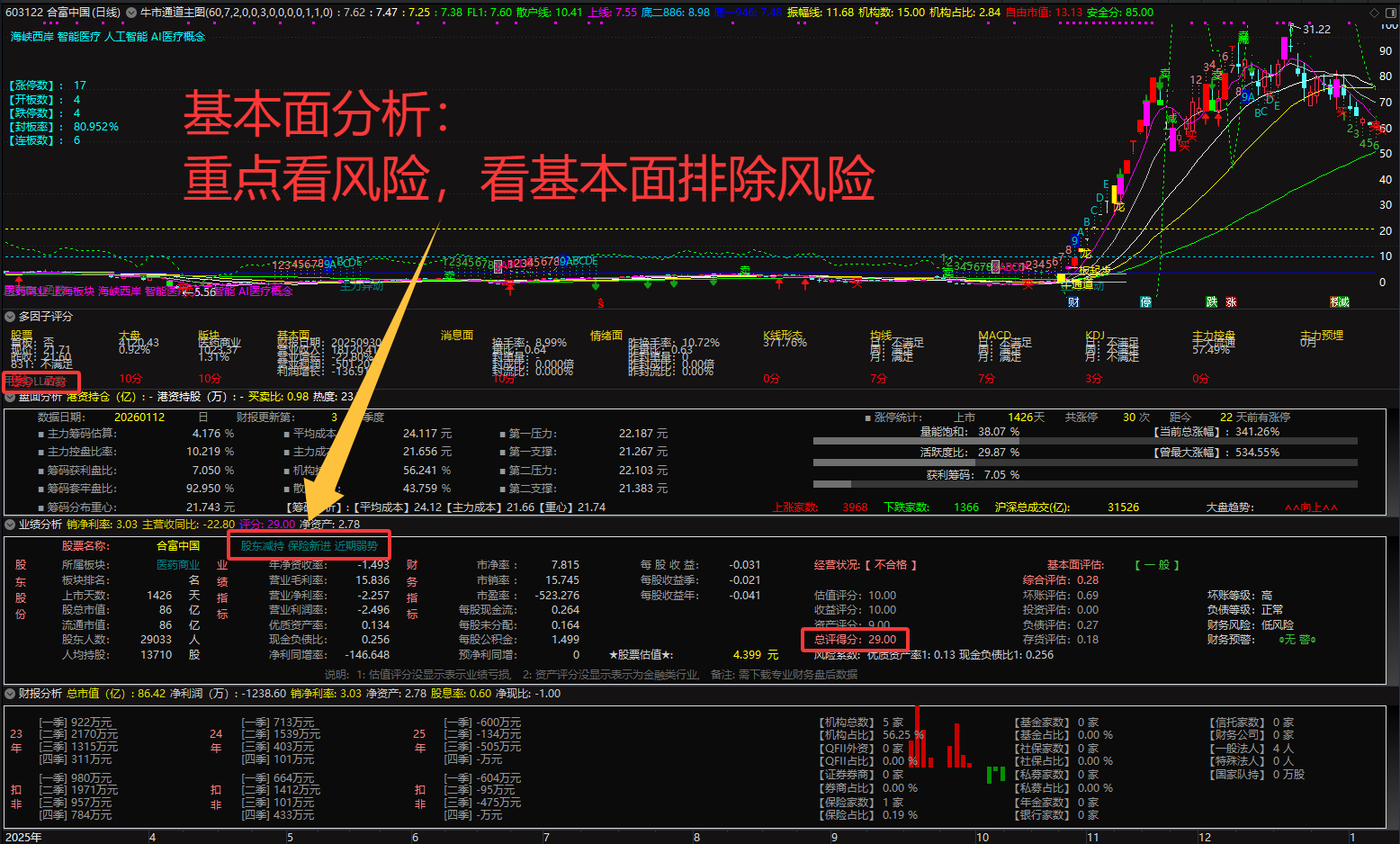
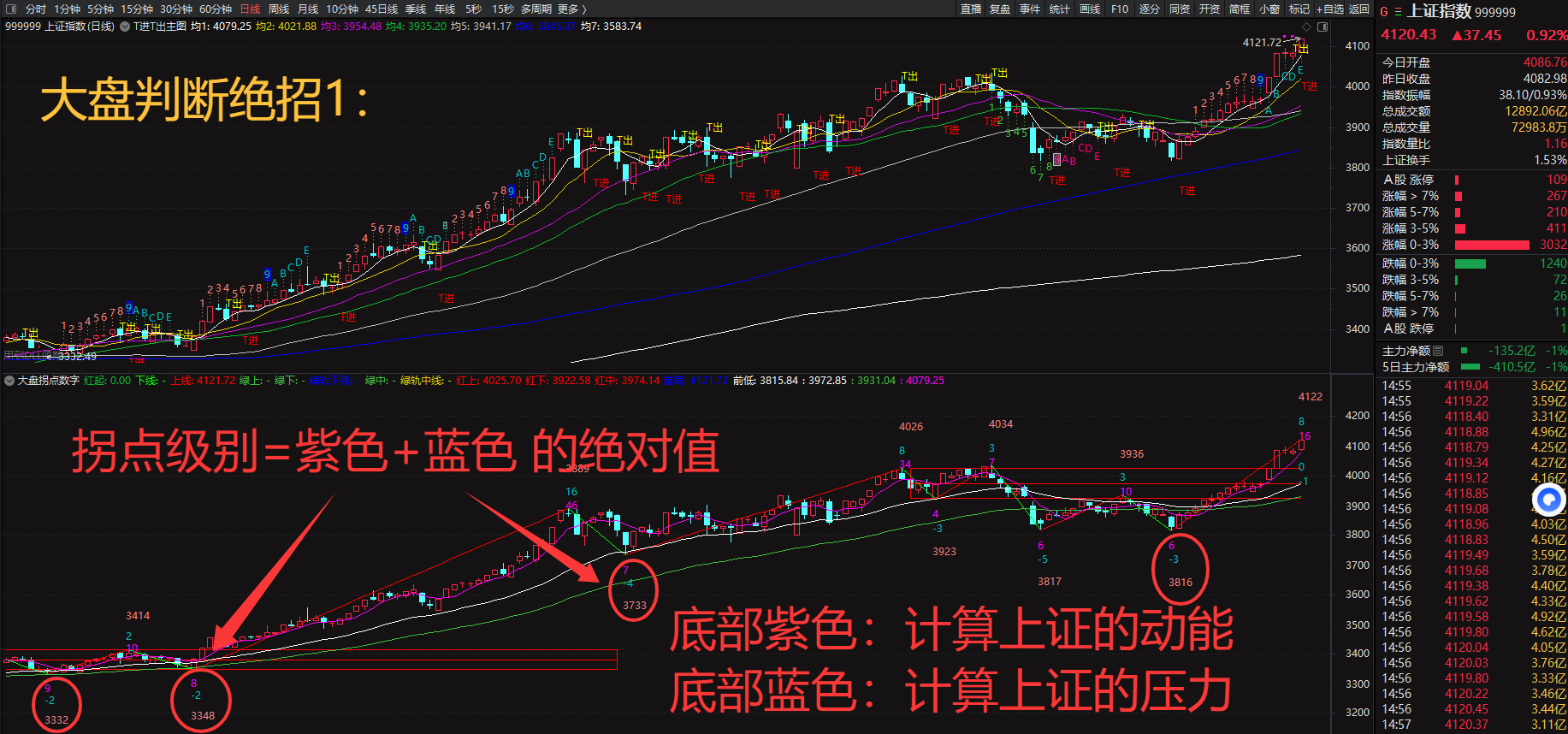
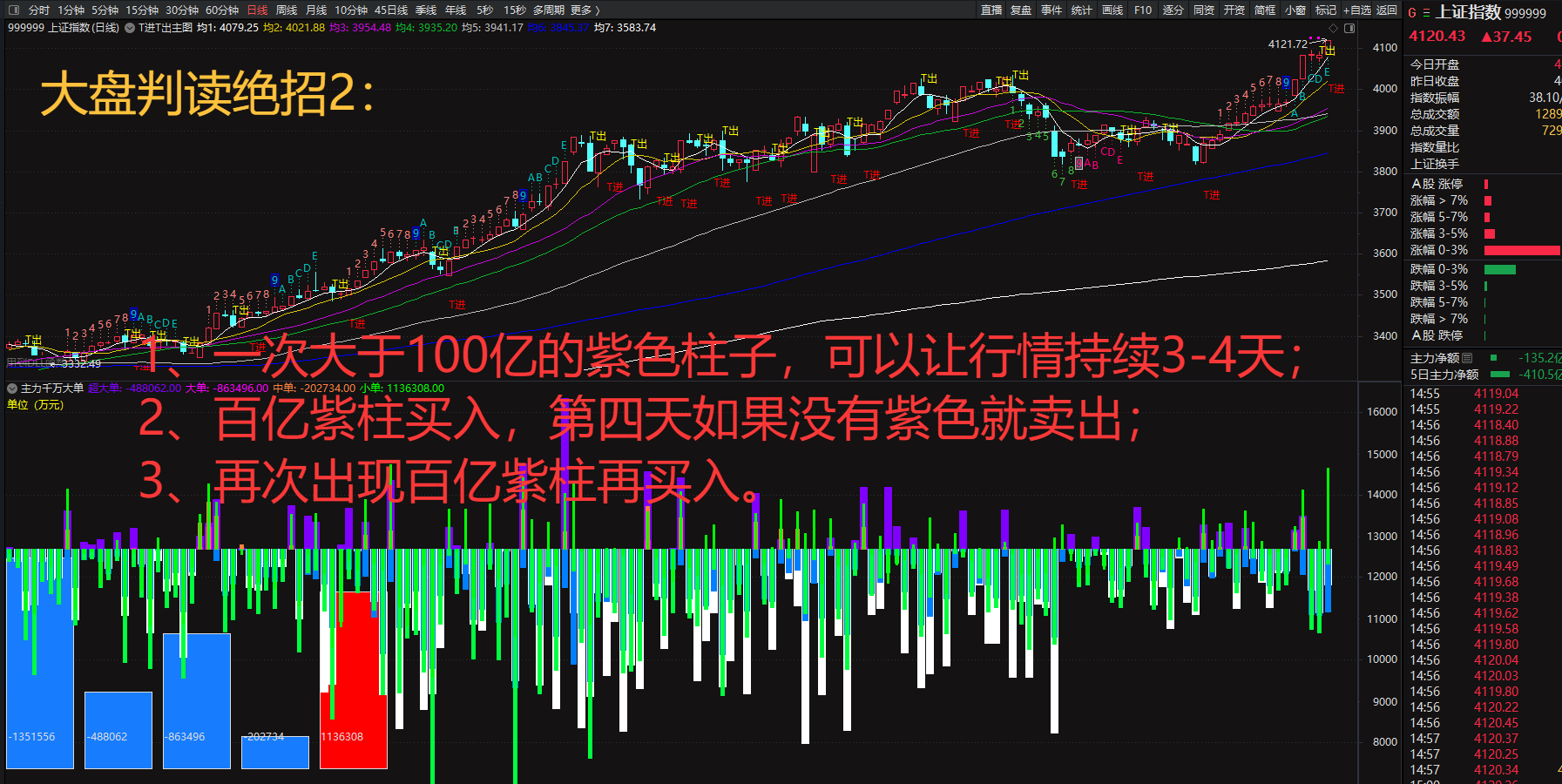
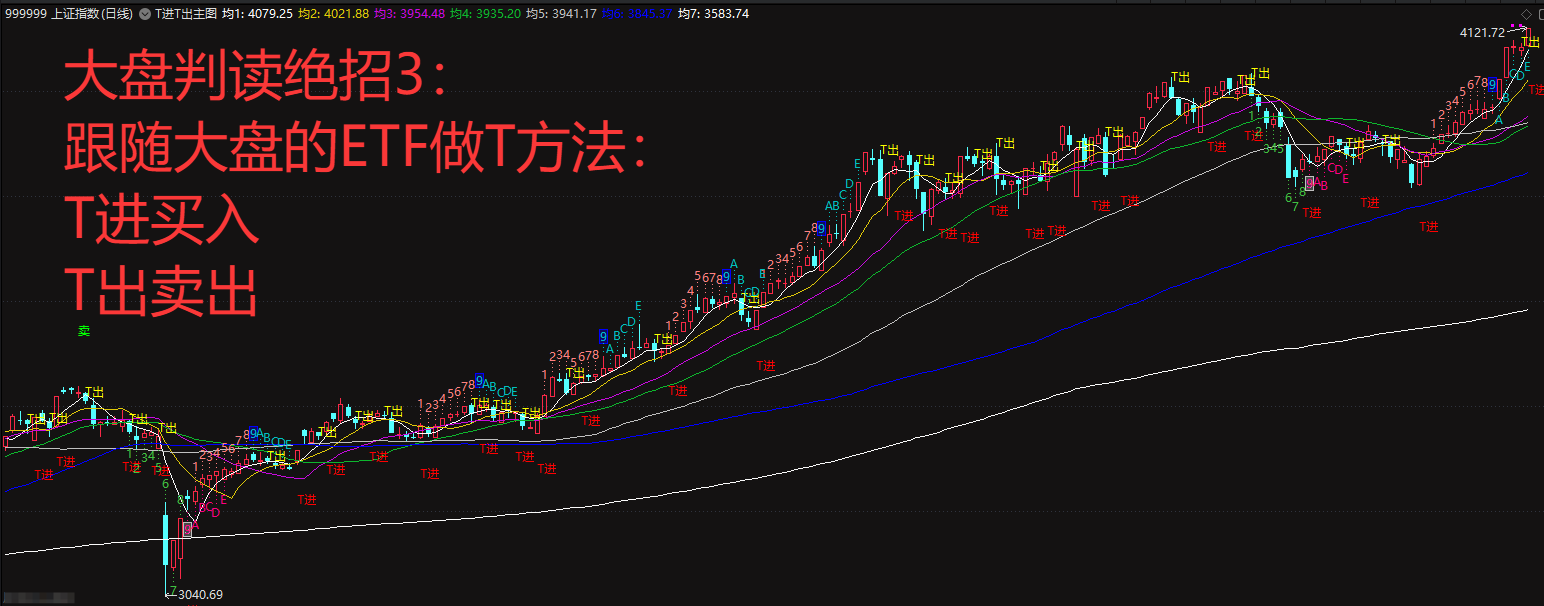
 暗盘资金排列、热点概念排序与成分股联动、126 人气#选谷宝指标
暗盘资金排列、热点概念排序与成分股联动、126 人气#选谷宝指标 AI炒股?我帮你踩过所有的坑了164 人气#选谷宝指标
AI炒股?我帮你踩过所有的坑了164 人气#选谷宝指标 【升级】「分时涨停条件4.0」指标套装上线3667 人气#选谷宝指标
【升级】「分时涨停条件4.0」指标套装上线3667 人气#选谷宝指标 【超快速度】通达信数据下载工具1083 人气#指标盒子
【超快速度】通达信数据下载工具1083 人气#指标盒子


 积分比较大,支持一下
积分比较大,支持一下


